Marktszenario
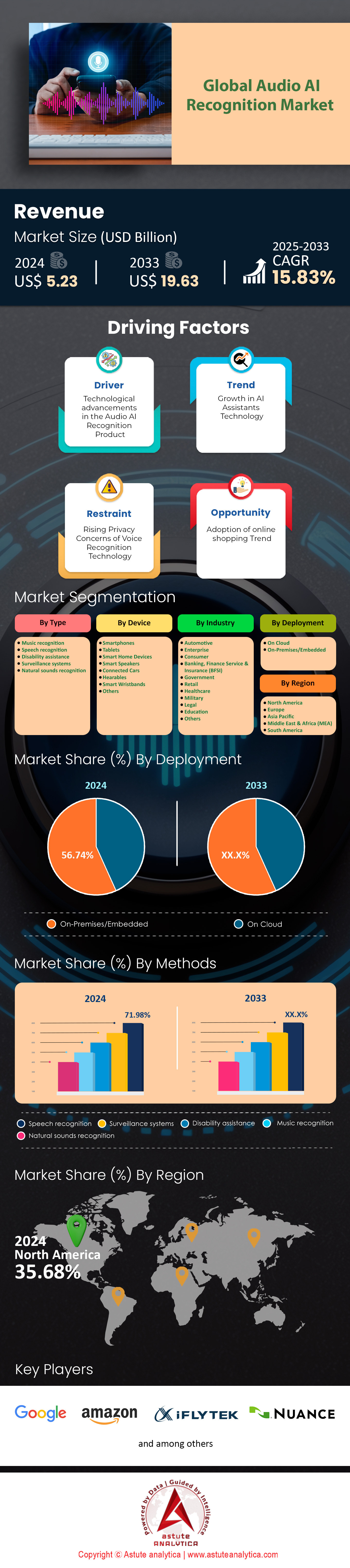
Der Markt für Audio-KI-Erkennung wurde im Jahr 2024 auf 5,23 Milliarden US-Dollar geschätzt und soll bis 2033 einen Wert von 19,63 Milliarden US-Dollar übersteigen, was einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 15,83 % im Prognosezeitraum 2025–2033 entspricht.
Die Nachfrage nach KI-gestützter Audioerkennung steigt weiterhin rasant an, angetrieben von den wachsenden Erwartungen der Verbraucher an nahtlose Sprachinteraktionen und präzise Sprachanalyse. Im Zentrum dieses Booms stehen Technologien wie Deep Learning, neuronale Netze, natürliche Sprachverarbeitung und Stimmbiometrie. Sie alle werden für Anwendungen wie Echtzeit-Transkription, virtuelle Assistenten und Sicherheitsauthentifizierung eingesetzt. Zu den wichtigsten Endnutzern zählen Callcenter, medizinisches Fachpersonal und die Automobilindustrie, die alle leistungsstarke Sprachfunktionen für Aufgaben wie die Überwachung der Mitarbeiterleistung, die Dokumentation von Patientendaten und die Fahrzeugsteuerung benötigen. Im Jahr 2024 wurden 230 neue KI-fähige Mikrofonarrays und 67 sprachbasierte Sicherheitslösungen auf den Markt gebracht. Darüber hinaus integrierten 12 Produkte Wavelet-basierte Merkmalsextraktionsverfahren, um Störgeräusche in Umgebungen zu kompensieren.
Zu den wichtigsten Branchen, die KI-gestützte Audioerkennung einsetzen, gehören Banken zur Beschleunigung der Kundenverifizierung, Medienunternehmen zur Automatisierung der Content-Erstellung und Bildungseinrichtungen zur schnellen Transkription von Vorlesungen. Auch das Gesundheitswesen nutzt KI-gestützte Sprachlösungen zur Entlastung des medizinischen Personals, während Unterhaltungsunternehmen die Benutzererfahrung durch sprachgesteuerte Bedienelemente verbessern. Jüngste Softwareentwicklungen umfassen Echtzeit-Sprachübersetzungsmodule und dynamische Emotionserkennungs-Engines, die eine intensivere Nutzerbindung fördern. Im Jahr 2024 wurden 104 spezialisierte Sprachbiometrie-Angebote auf den wichtigsten Plattformen dokumentiert, und 61 globale Finanzinstitute integrierten die Sprachauthentifizierung in ihre Mobile-Banking-Apps. Zu den wichtigsten Geräten, die diese Fortschritte nutzen, gehören Smart Speaker, tragbare Hörgeräte, Infotainmentsysteme in Fahrzeugen und Mobiltelefone.
Führende Produkte im Markt für KI-gestützte Audioerkennung sind Google Assistant, Amazon Alexa, Apples Sprachsteuerung und IBM Watson Speech-to-Text. Sie zeichnen sich durch hohe Genauigkeit und vielseitige Integrationsmöglichkeiten aus. Marken wie Microsoft, Baidu und iFlyTek treiben die Innovation mit kontinuierlichen Verbesserungen bei Latenzreduzierung, Sprachabdeckung und Kontextverständnis voran. Im Jahr 2024 kamen weltweit 38 Sprachassistenten für Fahrzeuge auf den Markt, 29 neue Spracherkennungslösungen für Krankenhäuser wurden eingeführt und 15 Spiele boten Sprachmoderationsfunktionen. Darüber hinaus wurden weltweit 110 Implementierungen von KI-gestützter Sprachanalyse in Contact Centern erfasst. Dies zeigt, wie Unternehmen branchenübergreifend Audio-KI nutzen, um ihre Effizienz zu steigern und ein optimiertes Nutzererlebnis zu bieten.
Für weitere Einblicke fordern Sie ein kostenloses Muster an.
Marktdynamik
Treiber: Zunehmende Akzeptanz fortschrittlicher sprachgesteuerter Schnittstellen durch die Verbraucher, die hochgradig personalisierte, wahrhaft menschenähnliche Interaktionen ermöglichen
Der Haupttreiber im Markt für KI-gestützte Audioerkennung ist die steigende Nachfrage der Nutzer nach flüssigen, sprachgesteuerten Erlebnissen, die über einfache Befehlsfunktionen hinausgehen. Verbraucher fordern zunehmend intuitive Chatbots und Freisprechassistenten in Autos, Wohnungen und am Arbeitsplatz, was Unternehmen dazu veranlasst, Sprachverständlichkeit, Kontextverständnis und emotionale Intonation zu verbessern. Im Jahr 2024 brachten Entwickler 42 Smart-Home-Systeme mit integrierter Konversations-KI auf den Markt, die die Stimmung der Nutzer erkennen, während 35 Automobilhersteller ihre Armaturenbretter mit ausgefeilten Funktionen für natürliche Sprache ausstatteten. Das Bestreben nach differenzierten Sprachantworten führte außerdem zur Einführung von 19 neuen Bibliotheken, die auf die Erkennung individueller Sprachmuster ausgelegt sind. Gleichzeitig stiegen Nutzerbindung und -zufriedenheit dank 54 Lösungen, die einen Echtzeit-Sprachwechsel zwischen regionalen Dialekten ermöglichen.
Die steigenden Erwartungen an hochgradig personalisierte Interaktionen, wie beispielsweise Sprechererkennungsfunktionen, die Stimmen in Haushalten oder Büros mit mehreren Nutzern identifizieren, treiben die Akzeptanz weiter an. Diese Funktionalität ermöglicht personalisierte Empfehlungen für Musik, Nachrichten oder Termine. Im Jahr 2024 setzten 28 Unternehmen fortschrittliche Stimmbiometrie ein, um bis zu zehn verschiedene Sprecher in einer einzigen Umgebung zu unterscheiden. Darüber hinaus führten 17 Lösungen im Markt für Audio-KI-Erkennung die Echtzeit-Emotionserkennung ein, um die Reaktionen basierend auf dem Tonfall des Nutzers anzupassen. Diese Innovationen verdeutlichen, wie Unternehmen Sprach-KI nutzen, um eine nahezu menschliche Verbindung herzustellen und so die Markentreue und den Alltagskomfort zu stärken. Entwicklungsteams investieren zudem Ressourcen in die Optimierung des Akzentverständnisses und stellen 23 neue Frameworks für die akustische Modellierung vor, die unterschiedliche Aussprachen unterstützen. Mit der steigenden Akzeptanz dieser hochmodernen Sprachschnittstellen durch die Verbraucher gewinnt der Markt unaufhaltsam an Dynamik und wird so zu einem entscheidenden Faktor für die zukünftige Entwicklung der Audio-KI-Technologie.
Trend: Integration mehrsprachiger Sprachsynthese-Engines in plattformübergreifende digitale Ökosysteme für hochgradig immersive Interaktionen
Ein führender Trend, der den Markt für KI-gestützte Audioerkennung grundlegend verändert, ist die Entwicklung hin zu robuster, mehrsprachiger Sprachsynthese. Systeme wechseln dabei nahtlos zwischen verschiedenen Sprachen und Dialekten innerhalb eines einzigen Gesprächs. Diese Fähigkeit bildet die Grundlage für Echtzeitübersetzungen bei globalen Konferenzen, kollaborativen Online-Plattformen und regionsübergreifendem Kundensupport. Im Jahr 2024 stellten Forschungslabore 21 fortschrittliche Text-to-Speech-Engines vor, die natürliche Sprachmelodien in vier Sprachen gleichzeitig wiedergeben. Pionierentwickler entwickelten neun ausgefeilte Sprachfonts für unterschiedliche kulturelle Kontexte. Darüber hinaus erlebte die plattformübergreifende Integration einen rasanten Aufschwung: 14 neue Software Development Kits (SDKs) ermöglichen interoperable Sprachlösungen für Mobilgeräte, Desktop-Computer, Wearables und Fahrzeugsysteme. Diese Durchbrüche unterstreichen das Marktziel, Sprachmodelle und Sprachsynthese in einem vielseitigen Framework zu vereinen.
Die steigende Nachfrage nach immersiven Interaktionen in Unterhaltung, E-Learning und kollaborativen Arbeitsumgebungen verstärkt diesen Trend zusätzlich. Audio-KI-Lösungen bieten mittlerweile mehrsprachige Sprachausgabe für Massive Open Online Courses (MOOCs) und überbrücken so sprachliche Barrieren. Im Jahr 2024 führten 16 Streaming-Dienste mehrsprachige Synchronisationsfunktionen ein, die auf Deep-Learning-basierten Stimmen beruhen und muttersprachliche Nuancen möglichst naturgetreu wiedergeben. Gleichzeitig implementierten elf Universitäten weltweit adaptive Sprachlernsysteme mit zweisprachiger Sprachsynthese im Markt für Audio-KI-basierte Spracherkennung. Die Synergie zwischen lokalisierten Sprachmodellen und fortschrittlicher Sprachgenerierung optimiert die Nutzerinteraktion und sorgt dafür, dass Anweisungen, Gespräche und Medienerlebnisse in jeder gewünschten Sprache überzeugend wirken. Entwickler haben fünf spezialisierte Module mit Echtzeit-Skriptanalyse eingeführt, um den Sprachstil kontextabhängig anzupassen. Angesichts des anhaltenden Wachstums plattformübergreifender Ökosysteme positioniert sich Audio-KI durch diesen Trend als universelles Werkzeug zur Überbrückung globaler Kommunikationslücken und zur Bereicherung digitaler Erlebnisse.
Herausforderung: Gewährleistung eines robusten Schutzes akustischer Daten angesichts zunehmender Bedenken hinsichtlich des Missbrauchs erfasster Sprachinformationen
Die größte Herausforderung im Markt für KI-gestützte Audioerkennung besteht darin, Sprachdaten vor unbefugtem Zugriff, Manipulation und missbräuchlicher Verwendung zu schützen. Da Sprachmuster sensible biometrische Merkmale enthalten, befürchten Unternehmen und Verbraucher Identitätsdiebstahl, unbefugte Aufnahmen oder die missbräuchliche Auswertung von Daten. Im Jahr 2024 dokumentierten Sicherheitsanalysten 14 bedeutende Fälle von Hacking-Angriffen auf Sprachdaten in Callcentern. Gleichzeitig wurden 22 spezialisierte Lösungen entwickelt, um Sprachdatenströme in Echtzeit zu verschlüsseln und so Sicherheitslücken zu schließen. Zu diesen Schutzmaßnahmen gehört auch der Einsatz von vier fortschrittlichen Hash-Algorithmen, die speziell für akustische Daten optimiert sind. Um das Vertrauen der Nutzer zu erhalten, müssen Entwickler sicherstellen, dass die Datenerfassungsmethoden strengen Datenschutzrichtlinien entsprechen, insbesondere bei der Speicherung von Sprachdaten in Cloud-Infrastrukturen.
Das gestiegene öffentliche Bewusstsein für Stimmmanipulation verschärft die Herausforderungen im Markt für KI-gestützte Audioerkennung zusätzlich. Deepfake-basierte Angriffe und betrügerische Stimmimitationen zeigen, wie leicht aufgezeichnete Sprachproben missbraucht werden können, wenn sie nicht ausreichend geschützt sind. Im Jahr 2024 untersuchten fünf aufsehenerregende Studien den Missbrauch geklonter Prominentenstimmen zu kommerziellen Zwecken. Darüber hinaus forderten acht Regulierungsbehörden verbindliche Standards für die akustische Verschlüsselung in allen wichtigen Branchen. Unternehmen reagierten darauf mit Investitionen in fortschrittliche Protokolle zur Anomalieerkennung, was zur Entwicklung von neun spezialisierten Prüfwerkzeugen führte, die die unbefugte Nutzung gespeicherter Äußerungen aufdecken. Ein robuster Datenschutz ist nicht nur für die Einhaltung gesetzlicher Bestimmungen, sondern auch für die Wahrung der Markenglaubwürdigkeit in einem Markt, in dem das Vertrauen der Nutzer höchste Priorität hat, unerlässlich geworden.
Segmentanalyse
Nach Typ
Spracherkennung ist mit einem Marktanteil von über 71,98 % führend im Markt für KI-gestützte Audioerkennung. Grund dafür ist ihre breite Anwendung in verschiedenen Branchen und Verbraucherbereichen. Führende Anbieter wie Google Assistant, Amazon Alexa, Microsoft Azure Speech to Text, IBM Watson Speech Services und Apple Siri dominieren dieses Segment. So ist beispielsweise der Google Assistant in über 3 Milliarden Geräten weltweit integriert, während Amazon Alexa mehr als 85.000 Smart-Home-Geräte steuert. Microsoft Azure Speech to Text wird häufig in Unternehmensanwendungen eingesetzt und bietet Echtzeit-Transkriptionsfunktionen für umfangreiche Projekte. IBM Watson Speech Services ist ein wichtiger Akteur im Gesundheitswesen und im Unternehmenssektor; seine Lösungen werden von Tausenden von Organisationen weltweit genutzt. Nuance Communications, ein führendes Unternehmen im Bereich der medizinischen Transkription, hat Dragon Medical entwickelt. Mit über 300.000 medizinischen Fachbegriffen ist Dragon Medical die bevorzugte Wahl für die klinische Dokumentation.
Die Dominanz der Spracherkennung im Markt für KI-gestützte Audioerkennung beruht auf ihrer Fähigkeit, Benutzerfreundlichkeit und Produktivität zu steigern. Apples Siri verarbeitet jährlich Milliarden von Anfragen und verdeutlicht damit die starke Abhängigkeit der Verbraucher von sprachgesteuerten Interaktionen. Im Automobilsektor sind sprachgesteuerte Navigationssysteme in über 300 Fahrzeugmodelle integriert und verbessern so Sicherheit und Benutzerfreundlichkeit. Auch im Kundenservice findet Spracherkennung breite Anwendung: Callcenter bearbeiten täglich Millionen von Sprachanfragen. Das Gesundheitswesen profitiert ebenfalls erheblich, da Krankenhäuser Spracherkennungslösungen für die medizinische Transkription nutzen. Diese Anwendungen unterstreichen die Vielseitigkeit und Effizienz der Spracherkennung und machen sie zu einem Eckpfeiler des Marktes für KI-gestützte Audioerkennung.
Nach Geräten
Smartphones dominieren den Markt für KI-gestützte Audioerkennung mit einem Marktanteil von über 33 %. Grund dafür sind ihre weite Verbreitung und die zunehmende Nutzung von Sprachassistenten im Alltag. Google Assistant ist auf über 3 Milliarden Android-Geräten weltweit vorinstalliert, während Apples Siri in 40 Ländern verfügbar ist und damit ihre globale Reichweite unterstreicht. Samsungs Bixby, integriert in über 100 Millionen Galaxy-Smartphones, verdeutlicht die hohe Verbreitung von Sprachassistenten auf Mobilgeräten. Durchschnittlich interagiert der Smartphone-Nutzer 17 Mal pro Woche mit Sprachassistenten, vor allem für Aufgaben wie Nachrichten, Navigation und Schnellsuche. Darüber hinaus verarbeitet die Spracherkennung in Smartphone-Apps täglich Millionen von Transkriptionsanfragen, was die starke Nutzung widerspiegelt.
Die zunehmende Verbreitung von KI-gestützter Audio-Spracherkennung auf Smartphones wird durch Fortschritte bei Hardware und KI-Funktionen vorangetrieben. Qualcomms Snapdragon-Prozessoren mit neuronalen Verarbeitungseinheiten ermöglichen Spracherkennung in Echtzeit, während Huaweis Kirin-Chipsätze Offline-Sprachübersetzung in mehreren Sprachen unterstützen. Zu den beliebten Smartphone-basierten Audio-KI-Lösungen gehören Microsofts SwiftKey Voice Input, das von Millionen Android-Nutzern installiert wurde, und Baidus Sprachassistent, der sich an ein großes chinesischsprachiges Publikum richtet. Die nahtlose Integration dieser Tools in Messaging-, Produktivitäts- und Unterhaltungs-Apps fördert die Kundenbindung. Da Smartphones sich kontinuierlich mit besseren KI-Chips und optimierten Mikrofonen weiterentwickeln, wird ein weiterer Anstieg der Nutzung von KI-gestützter Audio-Spracherkennungssoftware erwartet.
Nach Branchen
Die Konsumgüterindustrie ist der größte Endabnehmer von KI-gestützter Audioerkennung, da diese in Alltagsprodukte und -dienstleistungen integriert wird. Sie hält einen Marktanteil von über 25,5 % und wird voraussichtlich auch in den kommenden Jahren mit einer jährlichen Wachstumsrate (CAGR) von 17,6 % weiter wachsen. Intelligente Lautsprecher wie Amazon Echo und Google Nest sind weltweit über 200 Millionen Mal im Einsatz und unterstreichen damit ihre weite Verbreitung in Privathaushalten. Sprachgesteuerte Fernseher von Marken wie LG und Samsung finden sich in Millionen von Haushalten und belegen die Beliebtheit der freihändigen Steuerung von Unterhaltungselektronik. Wearables wie die Apple Watch und Fitbit integrieren Sprachassistenten für schnelle Abfragen. Die Apple Watch verkauft sich jährlich millionenfach, um die steigende Kundennachfrage zu decken. Auch kabellose Ohrhörer mit Sprachassistenten, wie Apples AirPods, erfreuen sich großer Beliebtheit und unterstreichen die Attraktivität der mobilen Audiosteuerung.
Im Konsumentenbereich sind Haushalte, persönliche Unterhaltungsgeräte und Wearables die wichtigsten Vertriebskanäle für die Audio-KI-Spracherkennung. Streaming-Dienste wie Netflix und Amazon Prime nutzen Sprachsuchmaschinen, um Nutzern die Navigation in umfangreichen Katalogen zu erleichtern und verarbeiten täglich Millionen von Inhaltsanfragen. Infotainmentsysteme im Auto, wie Apple CarPlay und Android Auto, bieten Millionen von Fahrern weltweit mehr Komfort und Sicherheit. E-Commerce-Plattformen wie Alibaba und Walmart ermöglichen ebenfalls sprachgesteuerte Einkäufe und verdeutlichen damit das große Interesse des Einzelhandels an Sprachtechnologie. Die Dominanz der Konsumentenbranche wird durch den Wunsch nach freihändiger Bedienung und personalisierten Interaktionen angetrieben, unterstützt durch starke Markenökosysteme und wachsende Anwendungsfälle
Durch Bereitstellung
Der Markt für KI-Audioerkennung ist mit einem Marktanteil von über 56,7 % führend im Bereich der On-Premise-Lösungen. Dies ist auf die gestiegenen Bedenken hinsichtlich des Datenschutzes und die regulatorischen Anforderungen in Branchen wie dem Gesundheitswesen, dem Finanzsektor und der Verteidigung zurückzuführen. Krankenhäuser beispielsweise bearbeiten täglich Tausende von medizinischen Transkriptionsaufgaben und setzen dabei auf On-Premise-Lösungen, um sensible Patientendaten zu schützen. Auch Banken verarbeiten Millionen von telefonischen Kundenserviceanrufen, weshalb die interne Verarbeitung für die Einhaltung der Datenschutzbestimmungen unerlässlich ist. Führende Anbieter wie Nuance, IBM und Avaya bieten lokalisierte Lösungen an, die in firmeneigenen Rechenzentren implementiert werden können und so die Sicherheit und Vertraulichkeit der Sprachdaten gewährleisten.
Neben der Datensicherheit nennen Unternehmen häufig die größere Integrationsflexibilität und die geringere Latenz als Gründe für die Wahl einer On-Premise-Lösung. Unternehmen mit bestehenden Telefonsystemen profitieren kosteneffizient von der Integration von On-Premise-KI-Lösungen, die eine nahtlose Anbindung an die bestehende Infrastruktur ermöglichen. Contact Center, die täglich Millionen von Sprachanfragen bearbeiten, profitieren von einer stabilen, internen Infrastruktur, die eine gleichbleibende Leistung gewährleistet. Anbieter im Markt für Audio-KI-Erkennung wie Genesys und Cisco bieten Enterprise-Suiten an, die auf den Einsatz in großem Umfang zugeschnitten sind und die Nachfrage nach On-Premise-Lösungen weiter steigern. Dieser Ansatz wird insbesondere von multinationalen Konzernen und Regierungsbehörden bevorzugt, die Wert auf Datensouveränität und operative Kontrolle legen.
Diesen Bericht anpassen + von einem Experten validieren
Greifen Sie nur auf die Abschnitte zu, die Sie benötigen – regionsspezifisch, unternehmensbezogen oder nach Anwendungsfall.
Beinhaltet eine kostenlose Beratung mit einem Domain-Experten, der Sie bei Ihrer Entscheidung unterstützt.
Um mehr über diese Studie zu erfahren: Fordern Sie ein kostenloses Muster an
Regionalanalyse
Nordamerika ist der größte Markt für KI-gestützte Audioerkennung, wobei die USA dank ihres fortschrittlichen Technologie-Ökosystems und ihrer großen Verbraucherbasis führend sind. Mit rund 332 Millionen Einwohnern bieten die USA ein riesiges Publikum für sprachgesteuerte Produkte und Dienstleistungen. Amazon mit Hauptsitz in Seattle hat über 105 Millionen Alexa-fähige Geräte vertrieben und damit die starke Akzeptanz in amerikanischen Haushalten unter Beweis gestellt. Googles Assistant, entwickelt in den USA, ist weltweit in über einer Milliarde Geräte integriert, ein bedeutender Anteil davon in Nordamerika. Apples Siri verarbeitet jährlich Milliarden von Anfragen und spiegelt damit seine weite Verbreitung in der Region wider. Microsofts Azure Cognitive Services und IBM Watson Speech Services werden von Unternehmen häufig eingesetzt und festigen die US-amerikanische Marktführerschaft zusätzlich.
Die führende Position der Region im Markt für KI-gestützte Audioerkennung ist auch auf die hohe Smartphone-Nutzung zurückzuführen – allein in den USA gibt es rund 294 Millionen Smartphone-Nutzer. Risikokapital für KI-Startups fließt weiterhin in großem Umfang, mit Milliarden von Dollar, die in Sprachtechnologie und verwandte Innovationen investiert werden. Diese finanzielle Unterstützung fördert die Entwicklung fortschrittlicher Funktionen wie die Erkennung mehrerer Akzente und die mehrsprachige Live-Übersetzung. Zudem rüsten die Telekommunikationsanbieter in Nordamerika zügig auf 5G auf, was eine nahezu sofortige Verarbeitung von Audioanfragen auf Smartphones ermöglicht. Die technikaffine Bevölkerung der Region, kombiniert mit starken finanziellen Ressourcen und einem gut entwickelten Ökosystem von Anbietern, sichert Nordamerika seine führende Position im Markt für KI-gestützte Audioerkennung.
Wichtige Unternehmen auf dem Markt für KI-Audioerkennung:
- Amazon.com, Inc.
- Uniphore
- Sprachwissenschaft
- SoapBox Labs
- Otter.ai
- Verbit
- Mobvoi
- Nuance
- iFLYTEK
- Sensorik
- Weitere prominente Spieler
Aktuelle Entwicklungen auf dem Markt für KI-Audioerkennung
- Die Übernahme von Amelia durch SoundHound AI: SoundHound AI, ein führendes Unternehmen im Bereich der künstlichen Sprachverarbeitung, hat am 8. August 2024 Amelia, ein renommiertes Unternehmen für KI-Lösungen für Unternehmen, für 80 Millionen US-Dollar übernommen. Diese Übernahme ist besonders bedeutsam, da sie die Kompetenzen von SoundHound im Bereich der künstlichen Intelligenz, insbesondere in der Spracherkennung und bei KI-gestützten Lösungen, erweitert.
- Strategische Akquisitionen von Capacity: Capacity, ein KI-Softwareunternehmen, tätigte im Jahr 2024 mehrere strategische Akquisitionen, um sein Angebot an Sprach- und Kontaktcenter-Lösungen zu stärken:
- Übernahme von LumenVox, einem in San Diego ansässigen Anbieter von Sprach- und Stimmtechnologie
- Übernahme von CereProc, einem Spezialisten für skalierbare synthetische Stimmen
- Übernahme von SmartAction, einem Anbieter von KI-gestützten virtuellen Agenten für Contact Center
- SoundHounds Übernahme von SYNQ3 Restaurant Solutions: SoundHound hat SYNQ3, einen Anbieter von Sprach-KI und anderen Technologien für die Gastronomie, übernommen. Diese strategische Akquisition zielt darauf ab, SoundHounds Sprachbestelllösungen für die Restaurantbranche zu stärken und die wachsende Bedeutung von Audio-KI in bestimmten Branchen zu unterstreichen.
- WaveForms AI-Finanzierung Ein ehemaliger OpenAI-Forscher gründete WaveForms AI, ein Startup, das sich auf die Entwicklung emotional ansprechender Sprachinteraktionen mithilfe von KI konzentriert, und sicherte sich eine Finanzierung in Höhe von 40 Millionen Dollar.
- Salesforce hat Tenyx, ein Unternehmen für KI-gestützte Sprachassistenten, das Branchen wie E-Commerce und Gesundheitswesen bedient, übernommen. Diese Akquisition steht im Einklang mit der Strategie von Salesforce, seine KI-Fähigkeiten in den Bereichen Spracherkennung und -interaktion auszubauen, und unterstreicht die wachsende Bedeutung von Audio-KI im Kundenbeziehungsmanagement und im Dienstleistungssektor.
- Im Juni 2024 schloss Amazon einen Vertrag mit dem KI-Startup Adept ab, der die Einstellung von Führungskräften und die Lizenzierung der Technologie umfasste. Obwohl der Fokus nicht ausschließlich auf Audio-KI liegt, zielt dieser Schritt darauf ab, Amazons Kompetenzen im Bereich der allgemeinen künstlichen Intelligenz zu stärken, was erhebliche Auswirkungen auf Fortschritte in der Audio-KI-Erkennung und der Verarbeitung natürlicher Sprache hat.
- Im April 2024 übernahm Microsoft Inflection AI und sicherte sich damit die Rechte, dessen KI-Modell über die Azure Cloud anzubieten. Durch diese Akquisition, die auch die Übernahme der Mitgründer und Mitarbeiter von Inflection umfasste, stärkt Microsoft seine KI-Sparte für Endverbraucher. Obwohl der Fokus nicht ausschließlich auf Audio-KI liegt, verbessert dieser Schritt Microsofts allgemeine KI-Kompetenzen, was sich voraussichtlich positiv auf Technologien zur Audioerkennung auswirken wird.
- Lenovo präsentiert „Lenovo AI Now“, einen lokalen KI-Agenten, der herkömmliche PCs in personalisierte KI-Geräte verwandelt. Die Plattform nutzt ein lokales, umfangreiches Sprachmodell (LLM) auf Basis von Metas Llama 3 und ermöglicht so die Echtzeit-Interaktion mit der persönlichen Wissensdatenbank des Nutzers.
- Microsoft hat Aktualisierungen für seinen Azure AI Speech-Dienst angekündigt. Dazu gehören die Verfügbarkeit von Videoübersetzung und die Unterstützung für OpenAI-Sprachausgabestimmen. Außerdem hat Microsoft die Azure AI Speech Toolkit-Erweiterung für Visual Studio Code veröffentlicht
- OpenAI sicherte sich eine bedeutende Finanzierungsrunde in Höhe von 6,6 Milliarden US-Dollar – eine der größten im Jahr 2024. Obwohl OpenAI in verschiedenen KI-Bereichen tätig ist, haben ihre Fortschritte bei Sprachmodellen erhebliche Auswirkungen auf Audio- und Spracherkennungstechnologien. Diese massive Finanzspritze dürfte die Forschung und Entwicklung im Bereich der KI-Technologien, insbesondere der Audioerkennung, beschleunigen.
Marktsegmentierungsübersicht:
Nach Typ
- Musikerkennung
- Spracherkennung
- Unterstützung für Menschen mit Behinderungen
- Überwachungssysteme
- Erkennung natürlicher Geräusche
Nach Gerät
- Smartphones
- Tabletten
- Smart-Home-Geräte
- Intelligente Lautsprecher
- Vernetzte Autos
- Hearables
- Intelligente Armbänder
- Andere
Durch Bereitstellung
- Auf Wolke
- Vor Ort/Eingebettet
Nach Branchen
- Automobil
- Unternehmen
- Verbraucher
- Bankwesen, Finanzdienstleistungen und Versicherungen (BFSI)
- Regierung
- Einzelhandel
- Gesundheitspflege
- Militär
- Recht
- Ausbildung
- Andere
Nach Region
- Nordamerika
- Die USA.
- Kanada
- Mexiko
- Europa
- Großbritannien
- Deutschland
- Frankreich
- Italien
- Spanien
- Polen
- Russland
- Asien-Pazifik
- China
- Taiwan
- Indien
- Japan
- Australien und Neuseeland
- ASEAN
- Übriges Asien-Pazifik
- Naher Osten und Afrika (MEA)
- VAE
- Saudi-Arabien
- Südafrika
- Rest von MEA
- Südamerika
- Brasilien
- Argentinien
- Restliches Südamerika
BERICHTSUMFANG
| Berichtattribute | Details |
|---|---|
| Marktgröße im Jahr 2024 | 5,23 Milliarden US-Dollar |
| Erwartete Einnahmen im Jahr 2033 | 19,63 Milliarden US-Dollar |
| Historische Daten | 2020-2023 |
| Basisjahr | 2024 |
| Prognosezeitraum | 2025-2033 |
| Einheit | Wert (Mrd. USD) |
| CAGR | 15.83% |
| Abgedeckte Segmente | Nach Typ, nach Gerät, nach Einsatzort, nach Branche, nach Region |
| Wichtige Unternehmen | Amazon.com, Inc., Google, Uniphore, Speechmatics, SoapBox Labs, Otter.ai, Verbit, Mobvoi, Nuance, iFLYTEK, Sensory und weitere namhafte Anbieter |
| Anpassungsumfang | Erhalten Sie Ihren individuell angepassten Bericht nach Ihren Wünschen. Fragen Sie nach individuellen Anpassungen. |
SIE SUCHEN UMFASSENDES MARKTWISSEN? KONTAKTIEREN SIE UNSERE EXPERTEN.
SPRECHEN SIE MIT EINEM ANALYSTEN
.svg)



Merkmale | Lizenzart | ||||
Datenbuch | Einzelbenutzer |   Mehrere Benutzer | Unternehmen | ||
| E-Zugang | ✓ | ✓ | ✓ | ✓ | |
Benutzerfreigabe | Nur für 1 Benutzer | Nur für 1 Benutzer | Bis zu 7 Benutzer | Unbegrenzter Benutzerzugriff | |
⨉ | ⨉ | ⨉ | ✓ | ||
Kostenlose Anpassung | Keine kostenlose Anpassung | Bis zu 30 Stunden Arbeit | Bis zu 60 Stunden Arbeit | Bis zu 80 Arbeitsstunden | |
Lieferformat |
| ⨉ | ✓ | ✓ | ✓ |
| ✓ | ⨉ | ✓ | ✓ | |
| ⨉ | ⨉ | ⨉ | ✓ | |
Analystenunterstützung | 2 Monate Analystenunterstützung | 4 Monate Analystenunterstützung | 7 Monate Analystenunterstützung | Ein Jahr Analystenbetreuung | |
Kostenloses Bericht-Update im nächsten Aktualisierungszyklus | ⨉ | ⨉ | ⨉ | ✓ | |
Kostenloses Branchen-Update (Innerhalb von 180 Tagen) | ⨉ | ⨉ | ⨉ | ✓ | |
Nutzen | Bis zu 10 % Rabatt nach dem Kauf | Bis zu 20 % Rabatt nach dem Kauf | Bis zu 30 % Rabatt nach dem Kauf | Bis zu 40 % Rabatt nach dem Kauf | |